Sections#
Sections is the fundamental concept of the HTTomo’s framework which is related to how the I/O operations and processing of data is organised.
Note
The main purpose of a section is to organise the data input/output workflow, as well as, chain together the methods so that the constructed pipeline is computationally efficient.
To better understand the purpose of the section it is also useful to read information about Chunks, Blocks and Memory Estimators.
Bellow we present different situations that can lead to the sections being organised in a specific manner.

Fig. 2 Here is a typical pipeline with a loader (L), 5 methods (M), and 4 data transfer operations (T) between methods.#
Sections are created when:
Re-slicing is needed, which is related to the change of pattern.
The output of the method needs to be saved to the disk.
The Side outputs is required by one of the methods.
Example 1: Sections with re-slice#
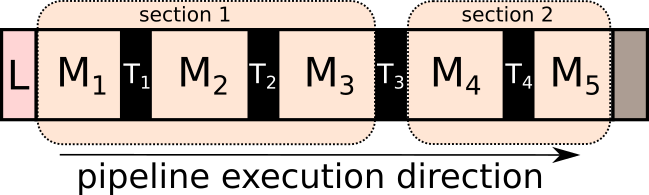
Fig. 3 Let us say that the pattern in methods M1-3 is projection and methods in M4-5 belong to sinogram pattern. This will result in two sections created and also Re-slicing operation in the data transfer T3 layer.#
Example 2 : Sections with re-slice and data saving#
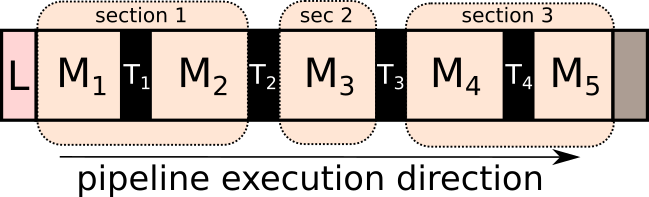
Fig. 4 In addition Example 1 situation, let us assume that we want to save the result of M2 method to the disk. This means that even though M1-3 methods can be performed on the GPU, the data will be transferred to CPU. The pipeline will be further fragmented to introduce another section, so that the data transfer T2 layer also saves the data on the disk, as well as, taking care to return the data back on the GPU for the method M3.#
Example 3 : Sections with side outputs#
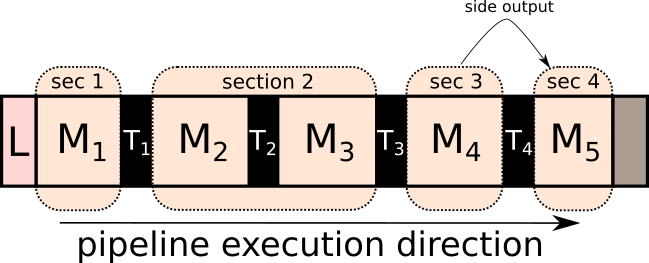
Fig. 5 Consider, again, Example 1. Here, however, M5 requests the Side outputs of the method M4. This, for example, can be because the reconstruction method M5 requires the Centre of Rotation (CoR) value of M4, where this value is calculated. This divides M4 and M5 into separate sections. Also notice that M1 needs the data to be saved on disk, so in total, it is a pipeline with 4 sections in it.#
Note
It can be seen that creating more sections in pipelines is to be avoided when building an efficient pipeline. Creating a section usually leads to synchronisation of all processes on the CPU and potentially, if not enough memory, through-disk operations.