HTTomo concept#
HTTomo stands for High Throughput Tomography pipeline for processing and reconstruction of parallel-beam tomography data. The HTTomo project was initiated in 2022 at Diamond Light source by the Data Analysis Group and it is written in Python. With the Diamond-II upgrade approaching, there is a need to be able to process bigger data in larger quantities and with high fidelity. With the support of modern developments in the field of High Performance Computing and multi-GPU processing, it is possible to enable faster data streaming and higher throughput for big data.
The main concept of HTTomo is to split the data into three-dimensional (3D) chunks/blocks and process them in parallel. The speed is gained using the optimised I/O modules, in-memory reslicing operations using MPI protocols, GPU-accelerated processing routines, and a capability of device-to-device GPU processing using the CuPy library. HTTomo orchestrates the optimal data splitting driven by the available GPU memory, which makes possible processing and reconstruction of big data even on smaller GPU cards.
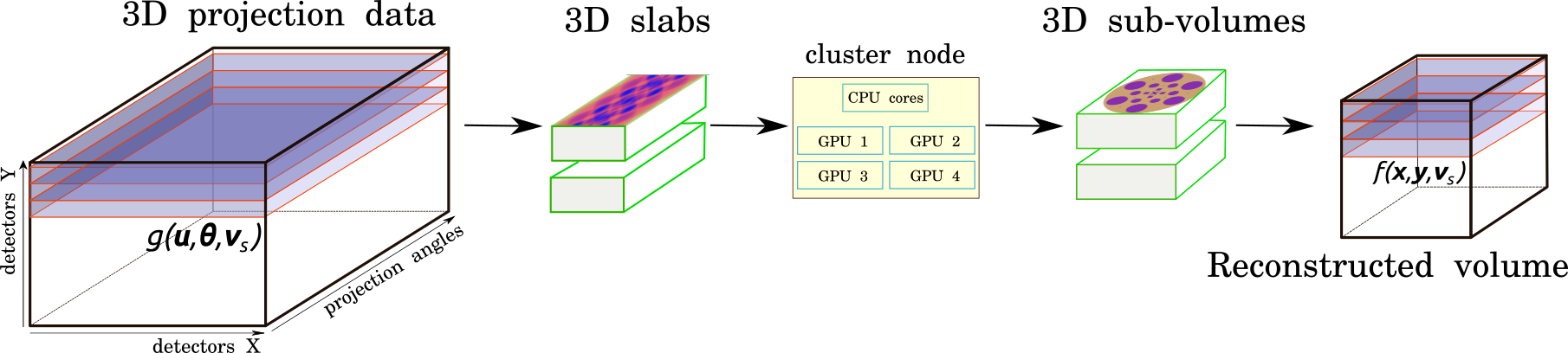
Fig. 1 HTTomo is tailored to work with 3D data, here 3D parallel-beam tomographic projection data is split and sent to a cluster with multiple GPUs for processing and reconstruction. Serial processing of data is also possible.#
HTTomo is a User Interface (UI) package and does not contain any data processing methods, but rather utilises other libraries as backends. Please see the list of currently supported packages by HTTomo in Supported libraries. It should be relatively simple to integrate any other modular CPU/GPU Python library for data processing methods in HTTomo, please see more on that in Developers section.
A complex data analysis pipelines can be built by stacking together provided Methods YAML Templates and Full YAML pipelines are also provided.