Model training is the process by which SuRVoS trains a machine learning classifier with a combination of the labels (annotations) provided by the user and the features generated through using the image filters. This trained model is then used to predict the missing labels for the rest of the supervoxels in the volume. This greatly speeds up the segmentation process when compared to manual annotation of the whole volume.
Model Training Component
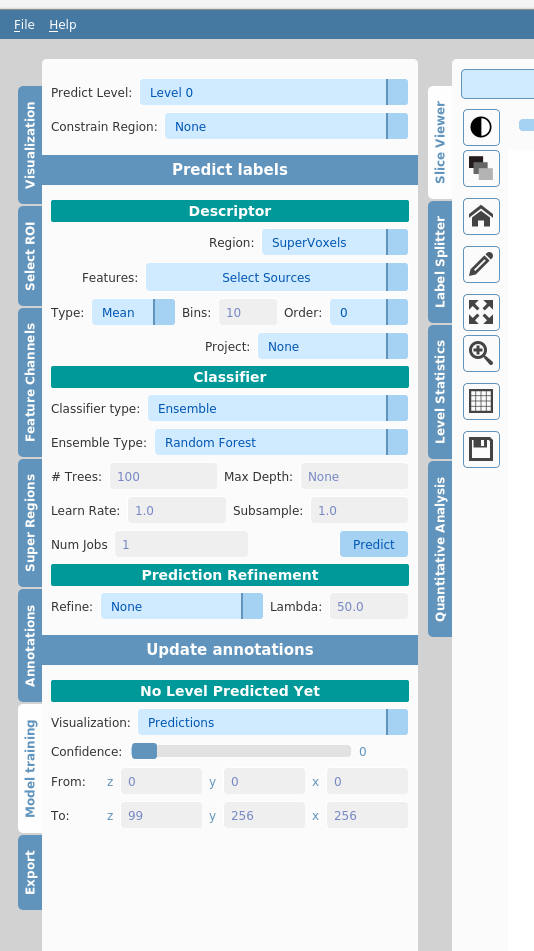
The components in the model training tab are designed to be used in sequence, from top to bottom. The first two dropdowns Predict Level and Constrain Region relate to the label hierarchy that exists in the Annotations tab. Predict Level (required) determines which level to train on and Constrain Region (optional) lets you constrain the training of the model to a subset region of the other level.
In the Descriptor section, the Region dropdown gives choice of whether to train on supervoxels or voxels. Features for training the classifier must be selected from the Features dropdown for training to proceed. The features calculated previously in the Feature Channels tab will be available here for selection. It is generally best to select a diverse set of features for model training, though there are no universal laws for what will work best for your data.
It is now possible to train the model using the Predict button. This will train the classifier selected in the Classifier type dropdown and then display the predicted labels in the visualisation pane.
Experimental Features
These new features are in development and are only available on request at present.
Save a Trained Classifier
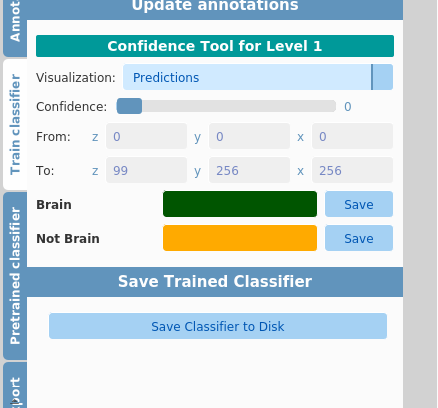
After performing training and prediction, the trained classifier can be saved by clicking on the Save Classifier to Disk button. A file save dialog box will appear to allow choice of filename and location. The default name is classifier.h5 in a classifers sub-directory of the SuRVoS workspace folder.